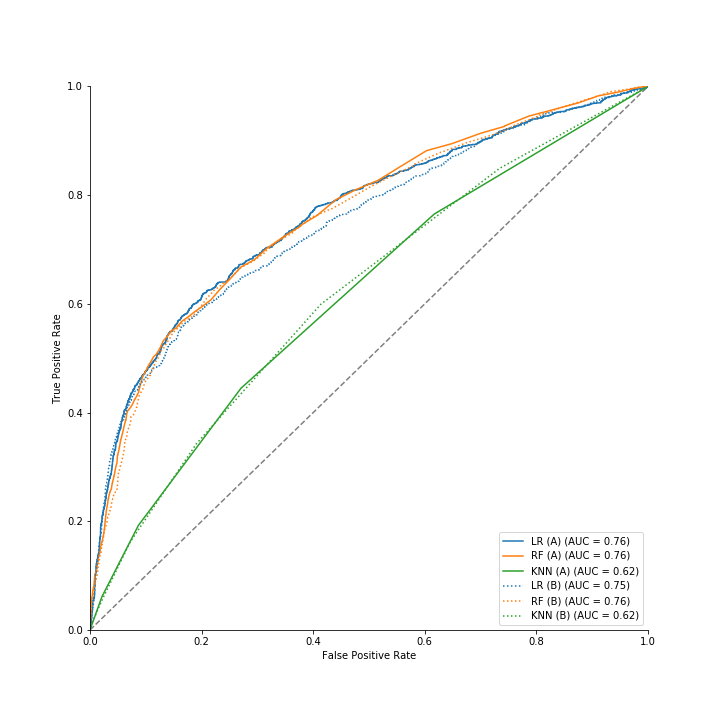
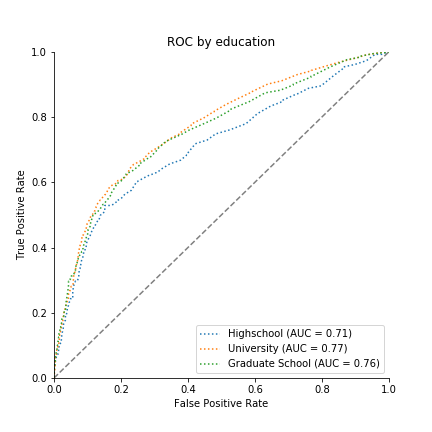
Methods: 2. Exploratory Data Analysis
A common observation in the field of algorithmic fairness is that the data used to train algorithmic decision-making systems already encodes outcomes of various historical discriminatory practices. Therefore a simple question worth asking is who is missing in this dataset. To this end, we compared the distributions of several demographic attributes in the dataset to that of the Taiwanese population overall.
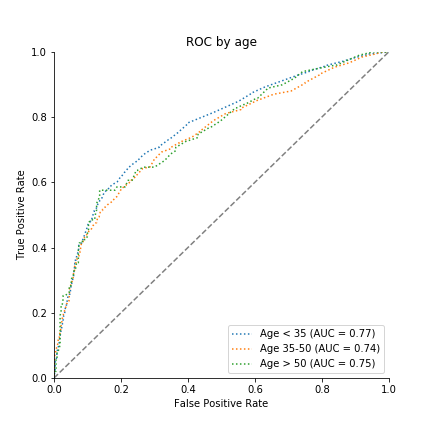
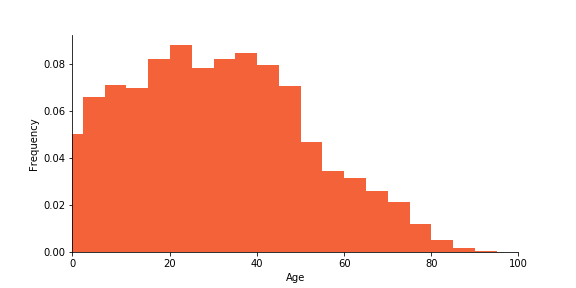
Age distribution of Taiwanese population
Age distribution of the credit data
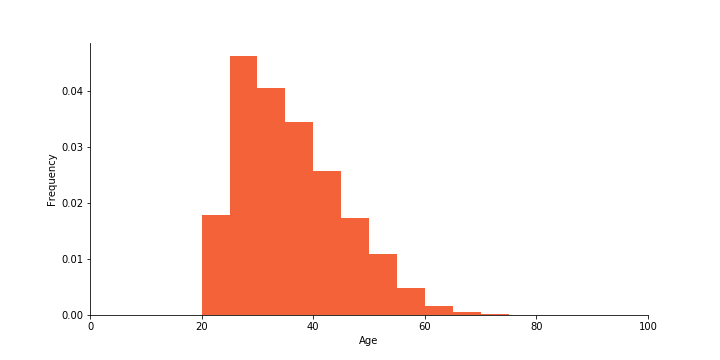
The people who are found in the credit card data are adults who tend to be younger than the general Taiwanese population. Especially elderly citizens are not represented. When faced with a new, unseen credit-card holder who is 70 or older, an automated decision-making system, such as one powered by logistic regression, may therefore likely extrapolate rather than interpolate from seen data.
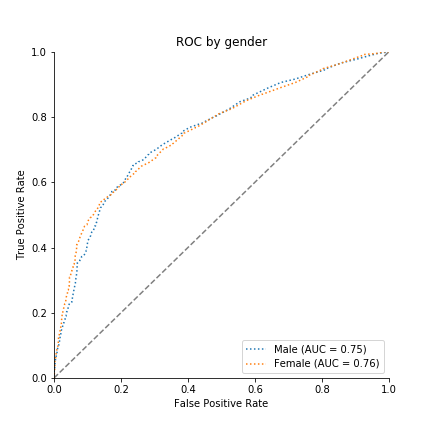
Gender presentation of Taiwanese population
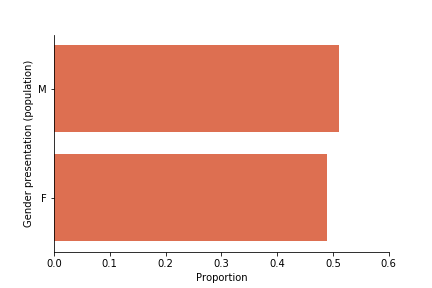
Gender presentation of the credit data
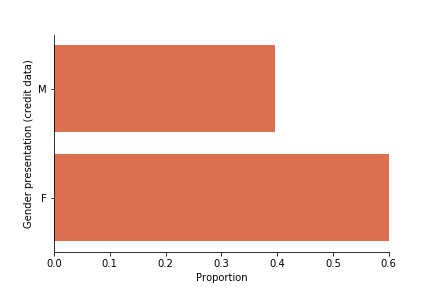
Women are overrepresented in the dataset. Further, the dataset’s M/F ontology reinscribes problematic binarized notions of gender, non-binary people are erased. [9]
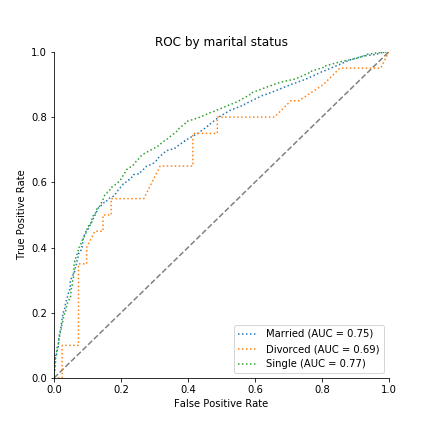
Marital Status of Taiwanese population

Marital Status of the credit data

While the majority of the Taiwanese population is married, the majority of the people represented in the credit dataset are single. The data further includes a disproportionately small number of divorced individuals. Widowed citizens are not represented explicitly in the credit data ontology.